Fine Tuning a Local LLM to Categorize Questions
As a fun personal project, I have been working on a chatbot for answering general questions about my household on anything from maintenance questions to doctor’s appointments.
The general idea is that the chatbot will get its household knowledge through RAG from querying a vector database, but for better results I have made the vector searches metadata aware.
Basically, I am running questions through a pre-processing step to categorize questions into known metadata categories (e.g. pool, car, hvac, cooking). The main goal of this is to narrow down the search space for vector ranking to only indexed entries that match the category of the question. As an example, the question “When did we replace our pool pump?” will be mapped to a category called “pool” before querying the Index database.
The hypothesis I want to test in this experiment is whether a very small local LLM can be fine-tuned to perform reliable question categorization when trained on a dataset of household-related questions
LLMs
In this project I am using two different local llms – Qwen 3:4B and Qwen 3:0.6B. The 4B parameter version is used for general question answering, while the super tiny 0.6B version is used to categorize questions. The whole premise of this experiment is to see if a tiny llm with only 600M parameters can be finetuned into a reliable classifier of household questions.
Finetuning
For finetuning I am using a popular open-source framework called Unsloth, which seems well suited for tuning local models like Qwen and Llama.
For training purposes my initial dataset consists of about ~850 data entries where I do a 70/15/15 percentage-based split into training data, eval data and test data respectively. Training data and eval data are used during training, while the test dataset is withheld and used to run a test post training. See section below for sample data:
The basic idea is to train the llm on a sufficient set of household questions to teach it to become a reliable question classifier.
Baseline
Before doing any finetuning, it’s important to establish a baseline to measure against. In this experiment the baseline is to try to use the original Qwen 0.6B model “as is” through prompting alone. A sample prompt used for the baseline can be found below:
Accuracy of Baseline model:
As one of my offline eval methods I have created a battery of ~130 integration tests to test the model with scenarios from a second dataset. For the baseline model, the results are poor. Out of 131 tests the model only categorized 13 questions correctly (~10% correct responses). See summary below:
When digging into the actual failures a few common patterns emerge:
- The model is mostly overusing broad labels like electric/appliances and missing most of the other categories (e.g pool, cooking, hvac).
- The model invents new categories (e.g. apartments) and doesn’t stick to the provided list of allowed categories
I have provided an excerpt from the test report below:
Finetuning – 1st attempt
The results from the baseline made it clear that a tiny model like Qwen 3 0.6B cannot provide reliable performance through just prompting alone.
As for the next experiment, I am using the same prompt as before, but I am doing model finetuning to teach the model how to categorize with greater accuracy.
I have included the finetuning script here in case you are interested in checking it out. At a high level I am leveraging Unsloth with QLora as the finetuning strategy. One note: The default fine tuning parameters provided by Unsloth provide a very good starting point. It’s been my experience that it’s more important to come up with a good dataset than worrying about tweaking the Unsloth values too much, at least to start.
One common pitfall to avoid though is overfitting on the training data, which is why it’s important to test the model on data not found in the training data. In addition to the static training/test data I have also incorporated a way to provide user feedback to amend the training data as a second channel during future retraining.
Result:
After running the battery of integration tests, I observed a clear improvement in prediction accuracy as seen in the report below:
The prediction accuracy is up from 10% to 79%, but I still see some clear patterns of incorrect results:
- The model now shows clear signs of heading in the right direction, but I see a pattern of only emitting fragments of the correct categories from the allowed list. Some examples are ac/air instead of hvac
- The model gets confused by semantically overlapping categories like water-based confusion from fountain, water heater and pool.
Finetuning – 2nd attempt
An easy improvement on the first fine tuning experiment would be to add a post processing step. This would allow me to normalize results where the prediction is semantically correct, but syntactically incorrect (e.g. ac, air). Another tweak would be to build more reinforcement into the prompt itself by providing more examples, telling the model what to do and not to do. I would say both ideas a reasonable, but it leads to more maintenance as more categories are added.
Instead, I wanted to see if I could tweak the finetuning approach slightly by making some changes to how I teach the model to map categories.
It turns out we can make a minor change to the prompt to improve accuracy even more compared to the 1st experiment. The tweak is actually just a simple change to the prompt where I map the categories to a two-character opaque IDs with no semantic overlap as seen in the sample below:
Now, I ask the model to output a fixed format code instead of a variable category string with potentially overlapping meaning (e.g. water-based categories).
The interesting part is that I see a very nice boost in performance from this simple change as seen in the summary below:
As you can see, prediction accuracy is now at ~92%, which is pretty accurate. It appears that asking for fixed, non-overlapping output helps the tiny qwen model when generating responses.
There are still a few misses though. I have included the specific failures below:
At this point the predictions are generally reliable, and the finetuned llm serves as a usable predictor in my chatbot, but there are still issues to work on. One issue that stands out is water heater -> pool, which is still likely due to the overlapping “watery” meaning between those two categories. To address this, I will likely have to revisit the training data and make it even more nuanced.
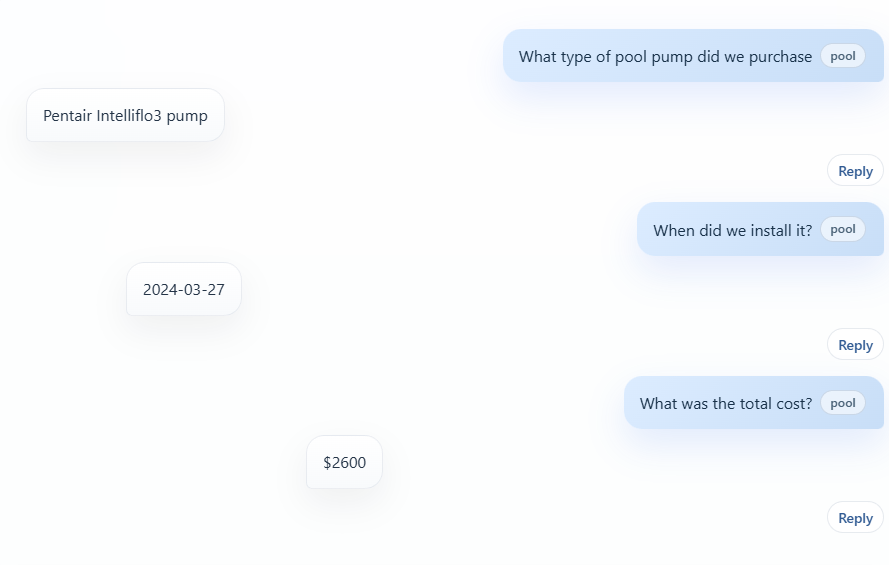
A sample chat interaction can be seen in the screenshot below. Pay special attention to the little category tag in the blue question bubbles (e.g. “pool”) since that is the part that is automatically classified by the tiny qwen 3:0.6B llm.
I have included the Github repo here in case you are interested in checking it out.
Update (6/22/2026)
While the main focus of this article was learning about fine tuning of tiny models, I did receive feedback from multiple readers that I should consider a simpler classification approach than llm fine tuning. This inspired me to run a new experiment using Logistic Regression as the classifier. If interested, you can find the new article here.