Creating a Chatbot Using a Local LLM
Indexing the Data
The key component in my solution is general RAG, so the first step is to pull in the content of the Wikipedia page and store it in an index DB (ChromaDB) for vector-based retrieval (i.e RAG). The best approach for indexing the data will depend on your particular use case, but a general guideline is to index data in chunks that convey a complete thought or idea. This will help with querying since you are much more likely to find results that match well with the semantic meaning of the input query. I tried a few different chunking strategies but landed on indexing Wikipedia pages in units of document sections. In addition to the raw content, I also store a hierarchical section title as metadata that can be used to categorize the data.
I have shared the code for preparing the sections with recursive section titles below:
Storing data as vector embeddings is key since it converts human readable text to a numeric, computer friendly, format that still represents the semantic meaning of the text. By passing the input query through the same embedding model we can search the vectorDB and locate chunk(s) that are semantically relevant to the query. In practice this means that different queries with different wording, but same meaning will likely match the with the same chunks.
Let’s look at the simple question: “What is your father’s name?”. Changing the wording to the less formal version “What is your dad’s name?” will still map the input query to a similar vector in embedding space. As a result, the chatbot will respond with the same answer based on retrieving the same data chunk. See screenshot below:

However, there are exceptions to this that may cause certain low signal queries to yield very poor matches in embedding space. Let’s look at one such sample question in: “What is Millenium Falcon?”. One of the challenges here is that embedding models are optimized for general semantic meaning but may underperform on short questions containing named entities (e.g. people, fictional objects). In these cases, it may yield better results to fall back on a keyword-based search like ngrams after first determining that the embedding space results are poor. I suspect there are multiple ways to implement this, but in this example, I use an LLM to rank the vector search results on a scale from 1-10 to determine relevance.
In my experience working on this chatbot, I achieved the best results from a hybrid query approach. I will show the flow below, but my general experience is that most queries find good matches in embedding space, but a few benefit from the fallback to ngrams (keyword-based matching). Let’s look at my implementation in the sections below:
Vector Search
I experimented with a few different flows for doing vector searches, but landed on the following:
Instead of doing a straight knn search to get the best matches, I try to augment the query with metadata filtering to further narrow down the search results when possible. Basically, I ask the LLM to categorize the question from a predetermined list of categories from all indexed chunks. If a suitable category is found, I retrieve only chunks that also match the metadata before creating the final inference prompt. As I mentioned before, the metadata is created from hierarchical section headers in the underlying Wikipedia document, so the success rate of this approach is highly dependent on the quality of these headers as descriptors of the section text. Unfortunately, with the Luke Skywalker page the results are mixed since the headers are often just names of various Starwars movies with limited context. However, other documents that I tested (e.g. Barrack Obama's Wikipedia page) had much more descriptive headers, which led to a much higher success rate in terms of matching on a single high-quality chunk.
I have included the prompt used for categorizing the input below:
I have also included the ChromDB query that includes the metadata filter criteria as well:
If the category based query, for some reason doesn’t provide an answer, I move on to asking the LLM to rate the results from the initial knn search on a scale from 1-10.
See the ranking prompt below:
In this implementation I am collecting all chunks with a score of 5 or above. The remaining chunks are discarded. One clear benefit from this is that we don’t end up taking up unnecessary space in the LLM’s context window for irrelevant responses. If none of the chunks are rated 5 or higher, the fallback on ngrams is triggered. I will discuss this approach more in the next section.
Ngram matching
In situations where none of the results from embedding space provide an acceptable answer to the question, the chatbot falls back to ngram matching. In my case I am building an inverted index consisting of all 1-gram, 2-gram and 3-gram entries from the chunks. You can think of the inverted index as a map of the individual grams from all chunks to the id of the corresponding chunks in the vector DB. Before querying, the input query is tokenized into grams that are mapped to entries in the inverted index. Finally, I pick the entries with the highest count of matching ids and use those in the final prompt.
Below is an excerpt from the inverted index where the property names represent grams and the numbers in the arrays are ids of chunks.
The code for looking up matches from the tokenized query can be found below:
I have also included a screenshot of an example where ngram matching produced the response to the question “What is Millenium Falcon?”.

Question Rewriting
One of the goals of the chatbot was to add support for multi-turn conversations where the user and the chatbot can exchange multiple connected messages or turns. I decided to implement this as a conversation thread in the UI, but this also requires some extra consideration on the backend.
One of the challenges with a multi-turn conversation is that individual messages may not be able to stand on their own in terms of adding enough context for the LLM to carry on the conversation. For usability reasons I wanted to avoid asking the user to repeat the context for every subsequent entry in the thread. As a workaround I decided to go with query rewriting on the server to make every message self-contained, but without manual intervention from the user. In my implementation, I feed all the messages in a particular thread to the LLM and ask it to rewrite the current question to add any necessary context from previous entries in the thread.
Let’s look at an example:
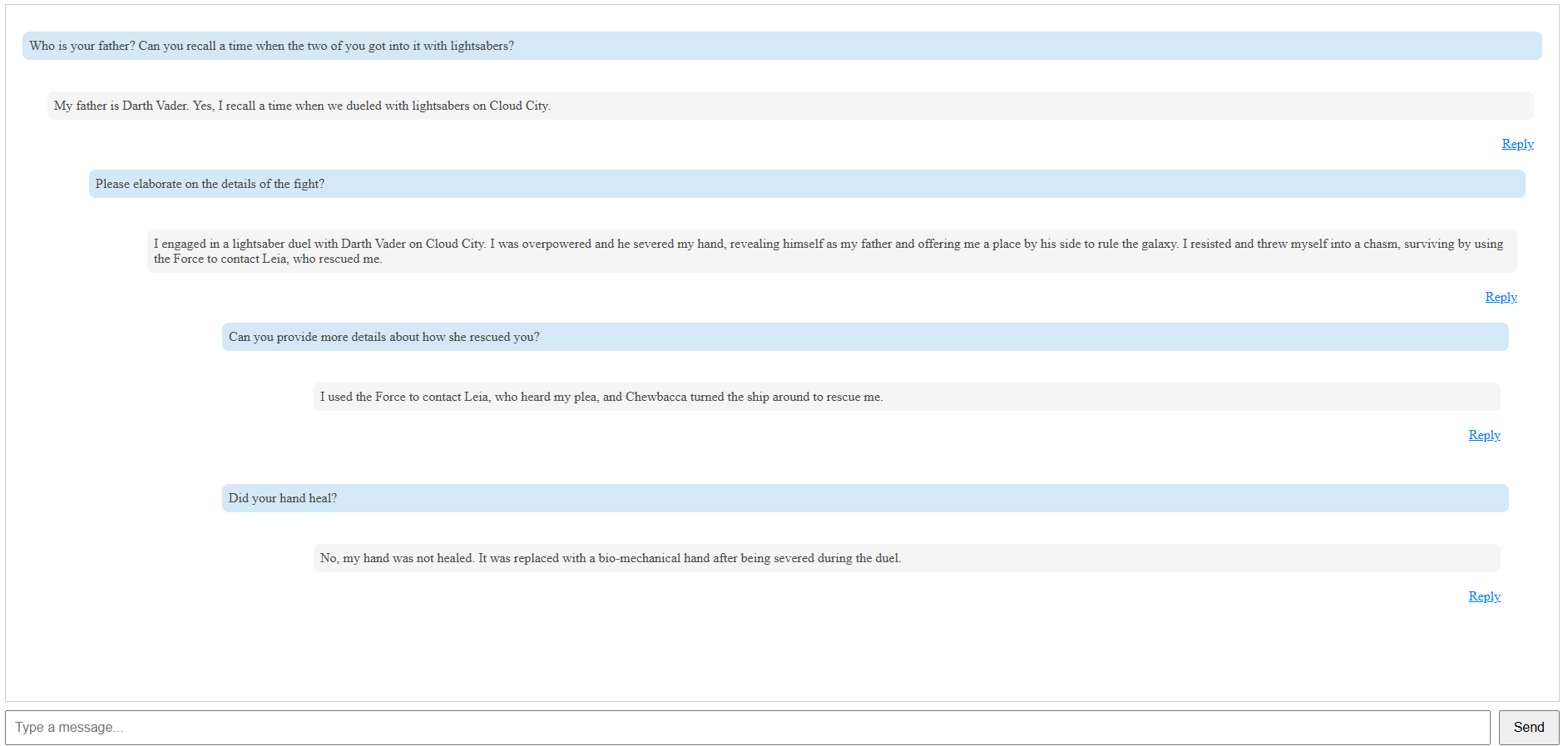
Deep in the conversation you can see the question: “Did your hand heal?”. The main challenge with this question is the lack of clarity and detail. As a result, you may get sub-par results if you submit it as-is to the LLM. There are probably multiple ways to address this, but in my implementation, I ask the LLM to rewrite the query to incorporate more context before sending it to the final prompt.
In this case, the vague question “Did your hand heal?” was rewritten by the LLM to the following: “Did your hand heal after being severed during the duel with Darth Vader on Cloud City, following your rescue by Leia?”
I have included the rewrite logic below:
Query Logic
Finally, I am showing the full logic for determining how to execute the hybrid search described in the sections above.
The code that shows my overall flow is included below:
The main prompt used for the chat responses can be found below. This is the prompt where the RAG content from the hybrid search is incorporated.
Conclusion
Overall, I am pretty happy with how the chatbot turned out. Some areas can still be improved, particularly around performance, but some of that is also a limitation of my hardware (only 8 GB of VRAM!). In case you are interested in taking a detailed look at the code, I've put it up on Github.